| yolov5遇到的问题 | 您所在的位置:网站首页 › jacket potato的马铃薯 › yolov5遇到的问题 |
yolov5遇到的问题
|
yolov5遇到的问题-在anaconda 虚拟环境中安装pytorch,cuda
问题一:TypeError: vars() argument must have __dict__ attribute问题二:AssertionError: CUDA unavailable, invalid device 0 requested解决方案接下来安装cuda版本的torch---这里我是在线安装
问题:>>> import torch,torch.cuda.is_available()==Falsecmd中检查cuda及cudnn是否成功安装及其版本参考安装pytorch遇到问题:
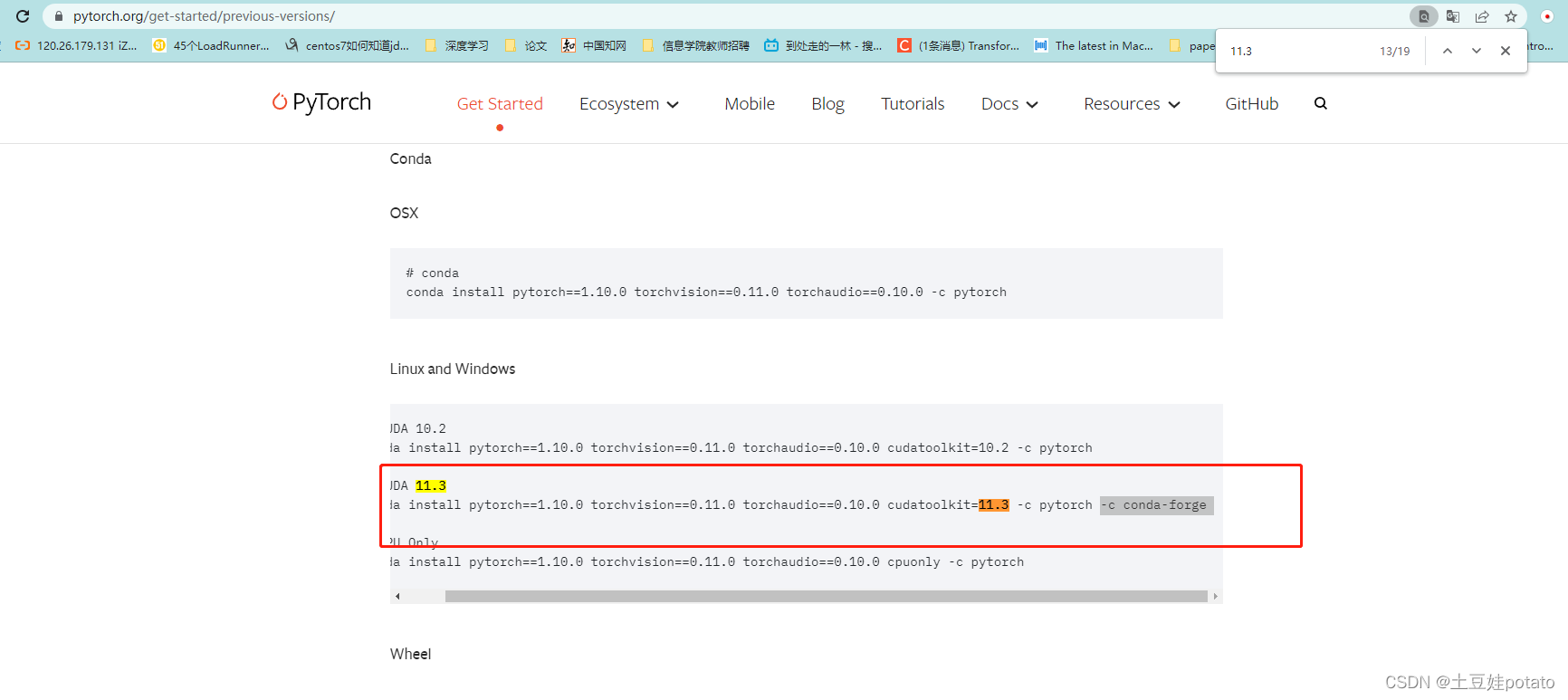
在anaconda 虚拟环境中安装pytorch一、创建虚拟环境最重要:下图是cuda:11.3对应的pytorch遇到bug该问题解决方法:---亲测有效!
接着执行下面的代码
问题:Exception: You need either charset_normalizer or chardet installed方法需要依赖库chardet或chardet-normalizer支持,尝试在安装requests前先pip install chardet,或使用这样命令安装: python -m pip install requests chardet
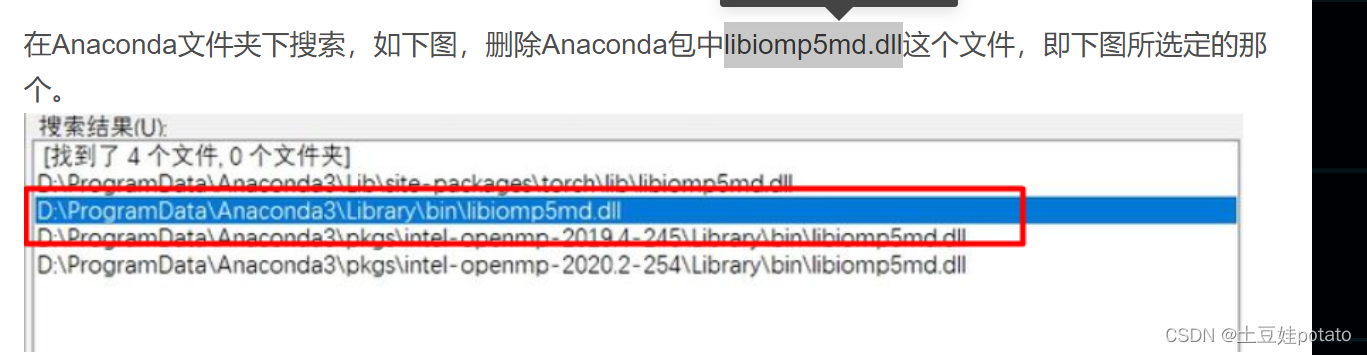
问题:RuntimeError: DataLoader worker (pid(s) 19340, 21256, 7988, 8180, 17600, 10208, 14972, 16948) exited unexpectedly问题:OMP: Hint This means that multiple copies of the OpenMP runtime have been linked into the program. That is dangerous, since it can degrade performance or cause incorrect results. The best thing to do is to ensure that only a single OpenMP runtime is linked into the process, e.g. by avoiding static linking of the OpenMP runtime in any library. As an unsafe, unsupported, undocumented workaround you can set the environment variable KMP_DUPLICATE_LIB_OK=TRUE to allow the program to continue to execute, but that may cause crashes or silently produce incorrect results. For more information, please see http://www.intel.com/software/products/support/.解决办法:=----可以解决!!!!下图中的我的解决不了
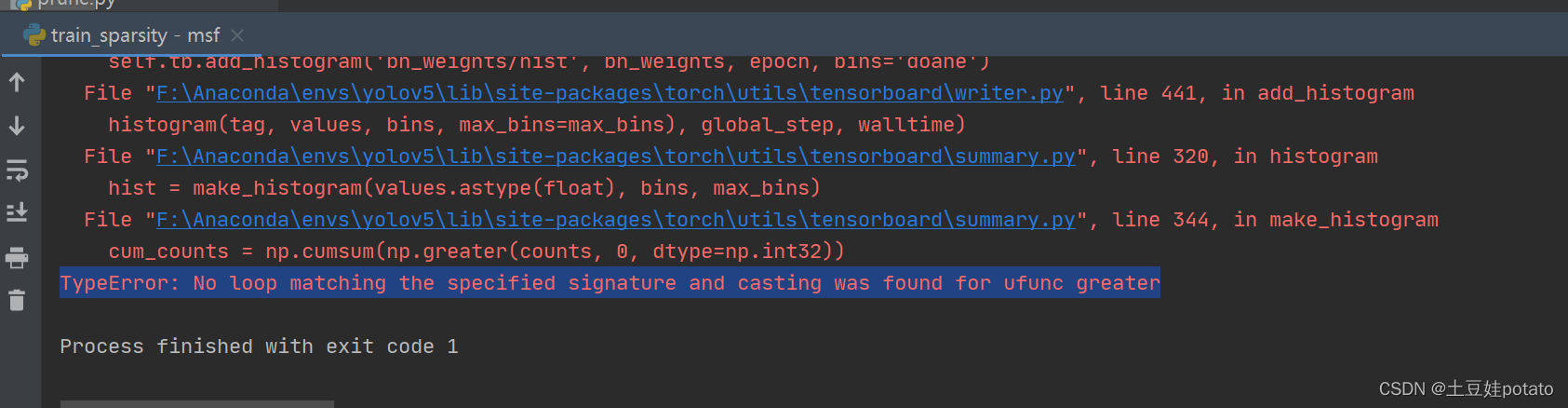
问题:TypeError: No loop matching the specified signature and casting was found for ufunc greater解决办法:推荐一个找bug的网站:[https://kaifa.baidu.com/](https://kaifa.baidu.com/)
问题一:TypeError: vars() argument must have dict attribute
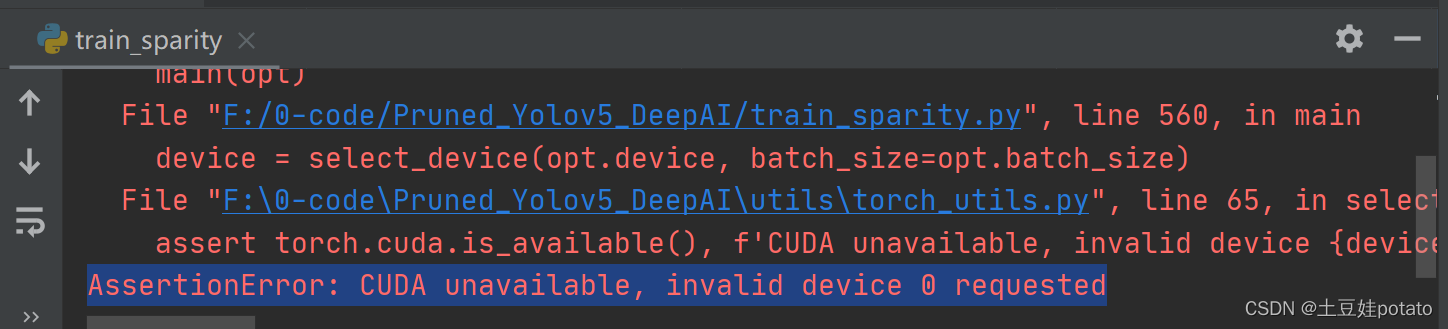
解决办法: 问题二:AssertionError: CUDA unavailable, invalid device 0 requested
cuda不可用报错,现实没有有效的驱动可使用 解决方案1、测试cuda是否配置正确 1)在终端输入 python3 import torch print(torch.cuda.is_available())
python import torch print(torch.version) 1.13.1+cpu
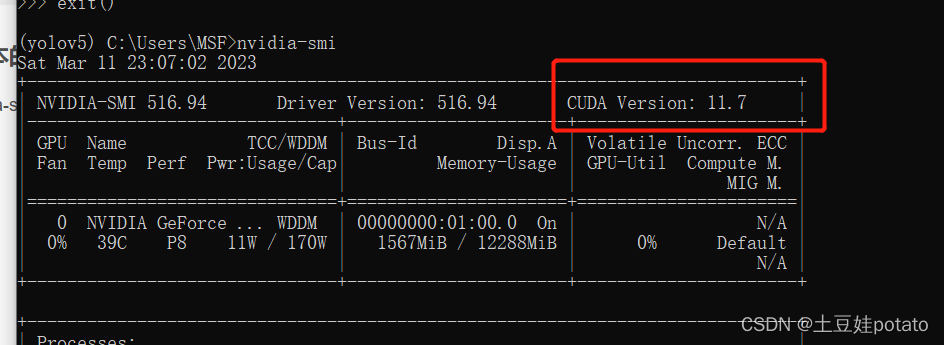
1:查看cuda版本:nvidia-smi【注意这不是查看anaconda中的cuda版本】 nvidia-smi
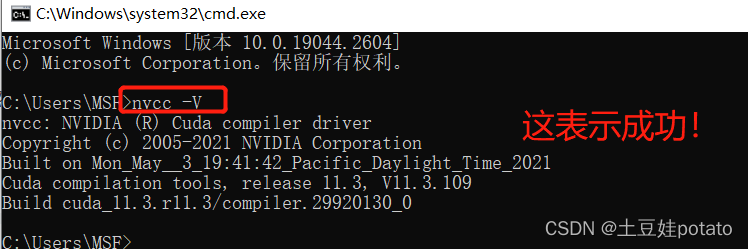
3.输入如下指令查看是否安装CUDA nvcc -V若安装完成显示下图
import torch print(torch.backends.cudnn.version()) 下图显示:None,表示未安装成功。
 原文链接:https://blog.csdn.net/qq_40968179/article/details/124240224 原文链接:https://blog.csdn.net/qq_40968179/article/details/124240224
2 .安装cuda和Pytorch 1、查看cuda版本: 
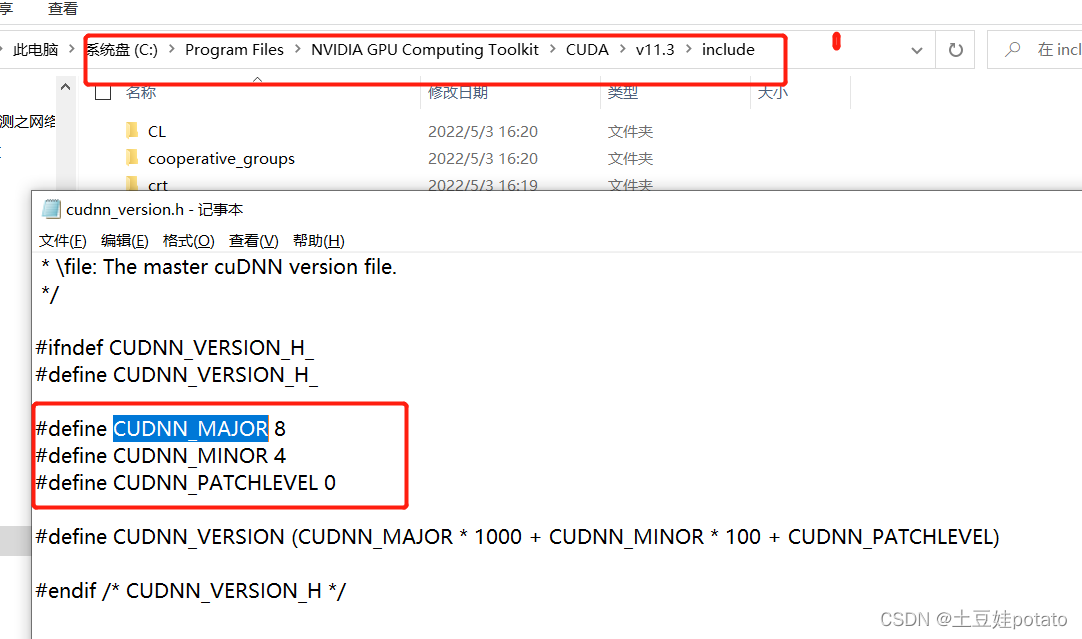 我的版本应该是8.4.0
参考 我的版本应该是8.4.0
参考
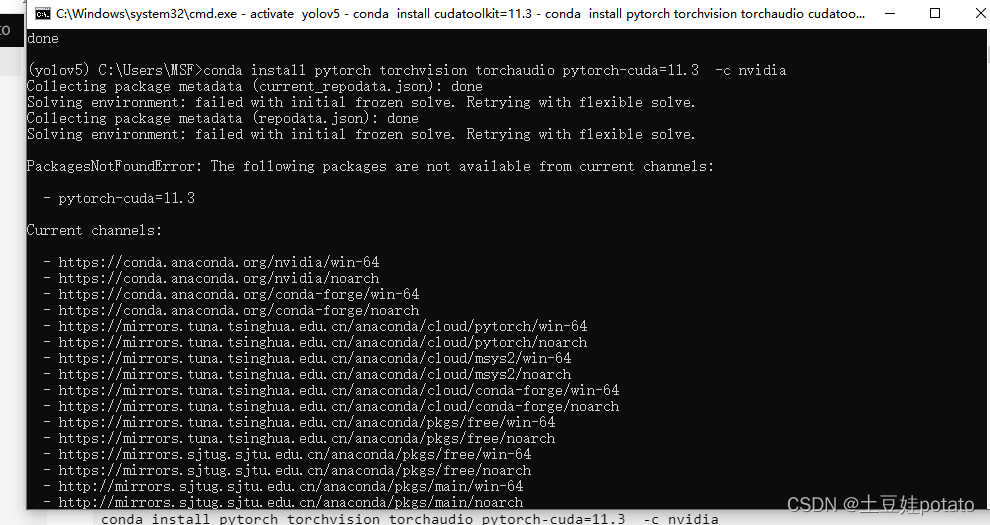
1、cuda和cudann安装,安装cuda和Pytorch 2.cuda和cudann安装 3.如何在anaconda虚拟环境中安装多个版本的CUDA,cudnn,pytorch,torchvision,torchaudio及进行环境配置手把手教学 安装pytorch遇到问题:1、Package pytorch conflicts for: 以管理员身份进入Anaconda Promot conda create -n pyTest python=3.8激活环境 activate pyTest查看cuda(cudatoolkit)和cudnn版本 以上的步骤看这篇博客:https://blog.csdn.net/qq_43919533/article/details/125694437 最重要:下图是cuda:11.3对应的pytorch 遇到bug
解决方法: 1.在anaconda prompt(base)下输入以下命令: conda config --add channels conda-forge 2.再次配置pytorch的虚拟环境,输入以下命令:conda create -n pytorch python=3.8 接着执行下面的代码 conda install pytorch==1.10.0 torchvision==0.11.0 torchaudio==0.10.0 cudatoolkit=11.3 -c conda-forge这条命令来自:https://pytorch.org/get-started/previous-versions/
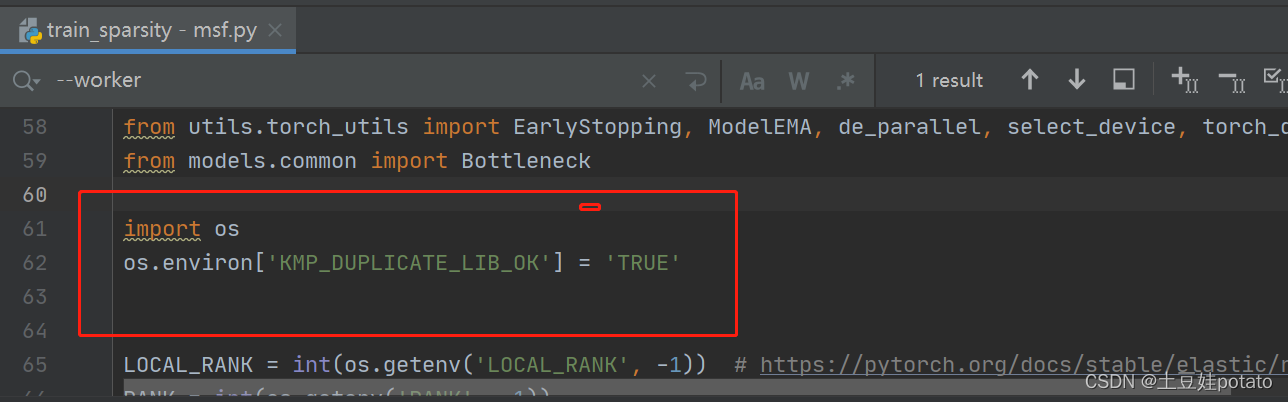
在代码前加入这两个代码行 import os os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
参考 :http://t.csdn.cn/gBAW8
https://blog.csdn.net/jacke121/article/details/128888756 推荐一个找bug的网站:https://kaifa.baidu.com/ |
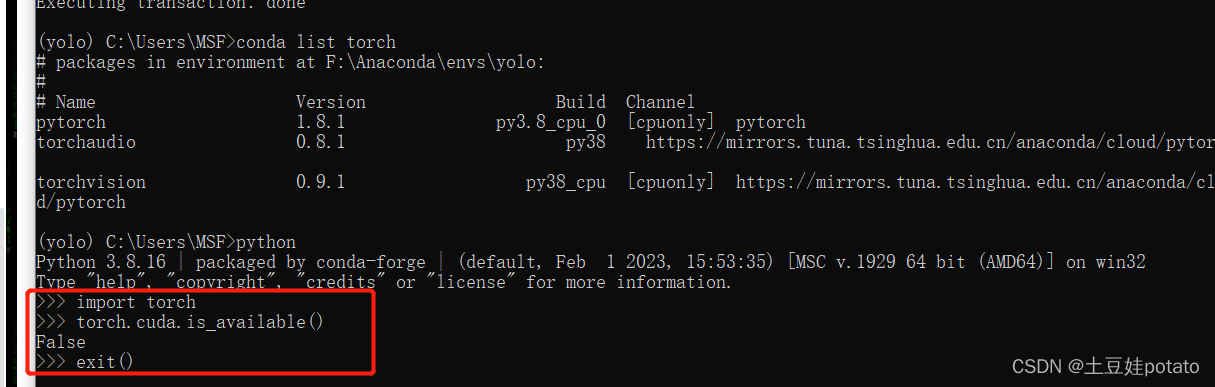
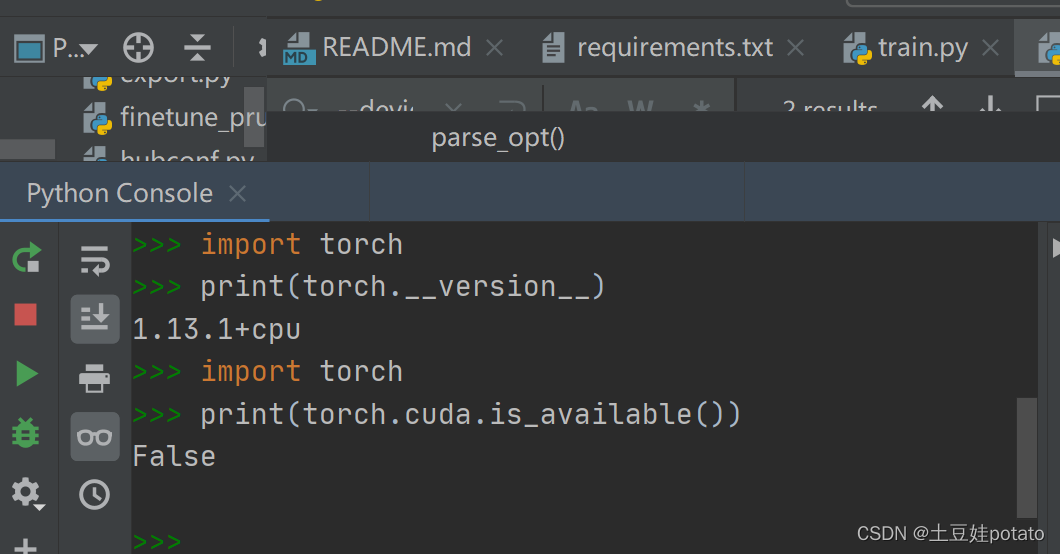 运行后输出的是False,说明cuda有问题。 继续找问题:有可能是pytorch的版本是cpu版本不是cuda版本的!
运行后输出的是False,说明cuda有问题。 继续找问题:有可能是pytorch的版本是cpu版本不是cuda版本的!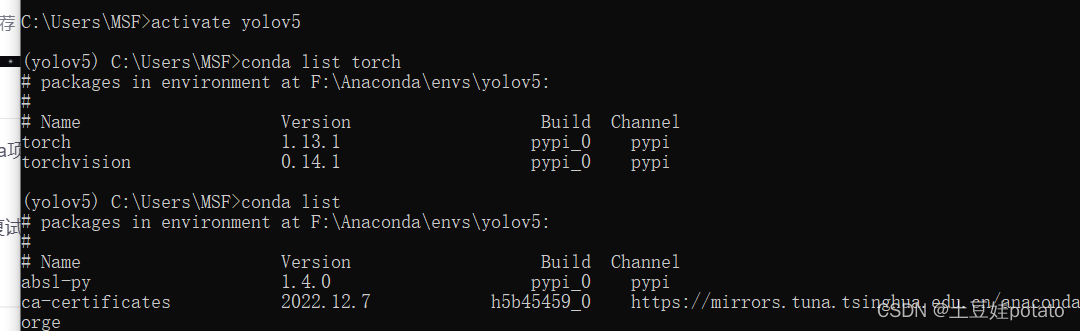 方法:查看torch的版本:
方法:查看torch的版本:
 查看anaconda环境中cuda的版本号: nvcc --version:
查看anaconda环境中cuda的版本号: nvcc --version: 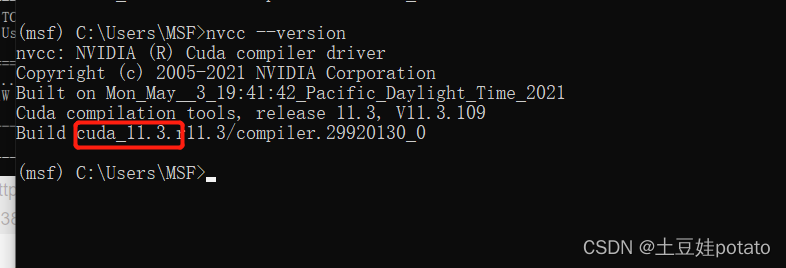
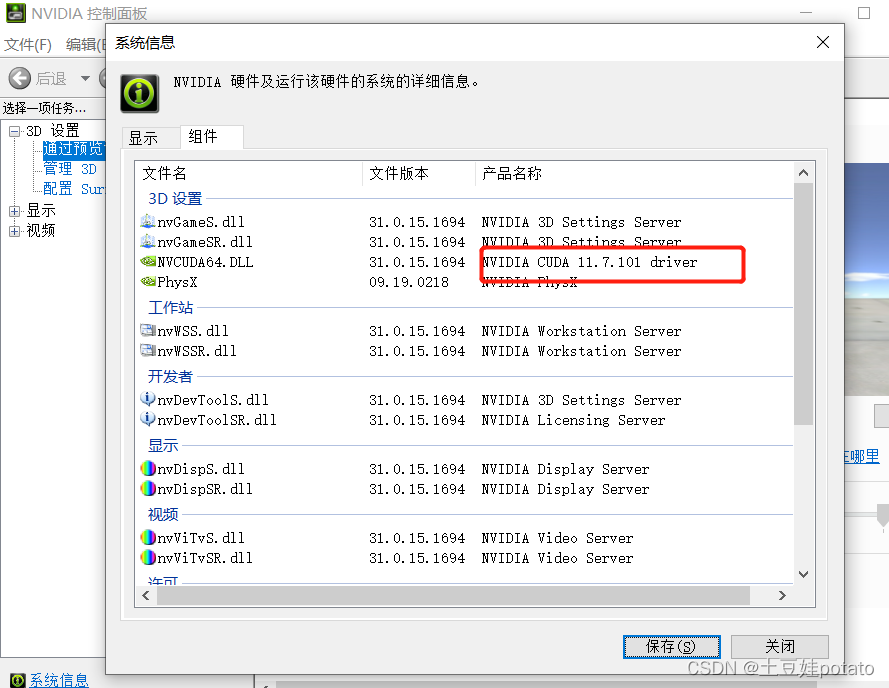
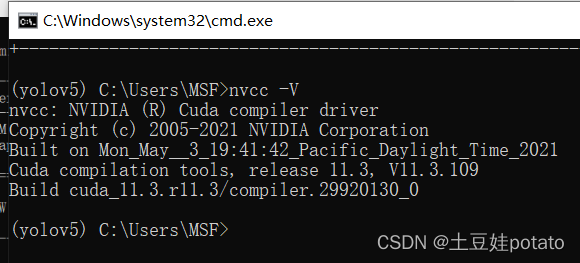 3. 查看cudnn版本
3. 查看cudnn版本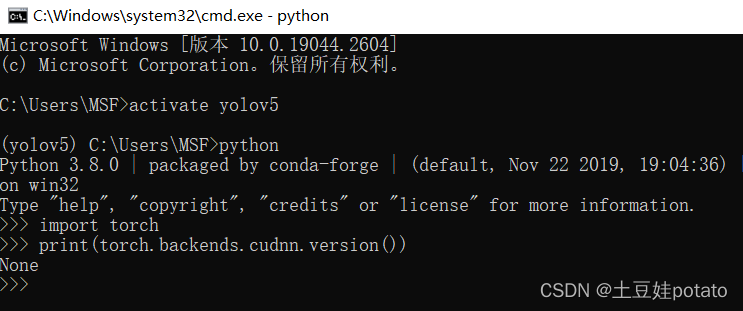
 T、具体安装看该博客:安装cuda教程,超级详细。
T、具体安装看该博客:安装cuda教程,超级详细。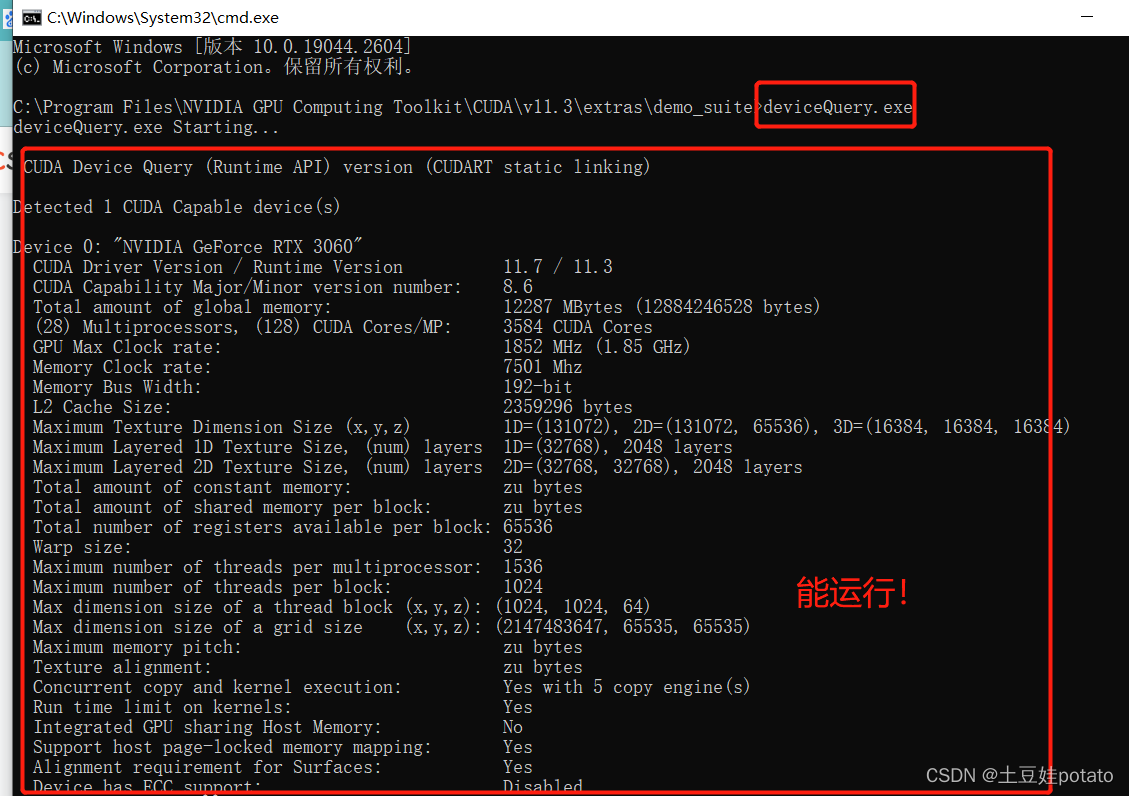
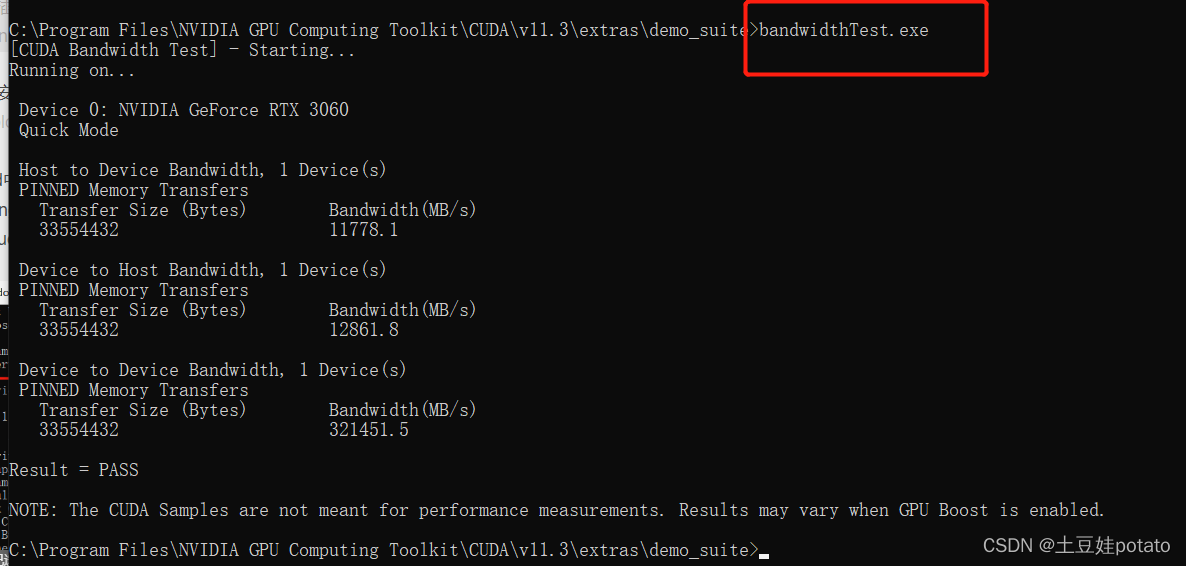 如果以上两个界面都出现,则cudnn也安装成功。
如果以上两个界面都出现,则cudnn也安装成功。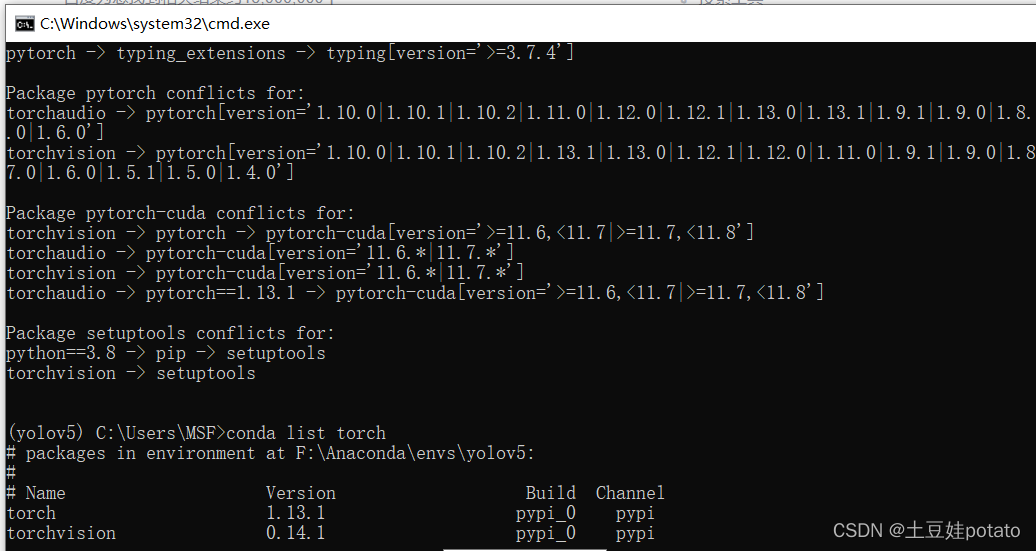
 安装成功:
安装成功: 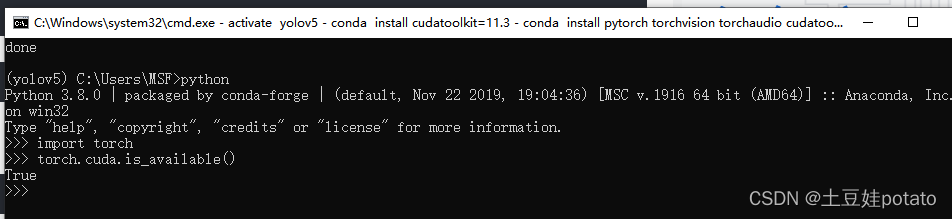
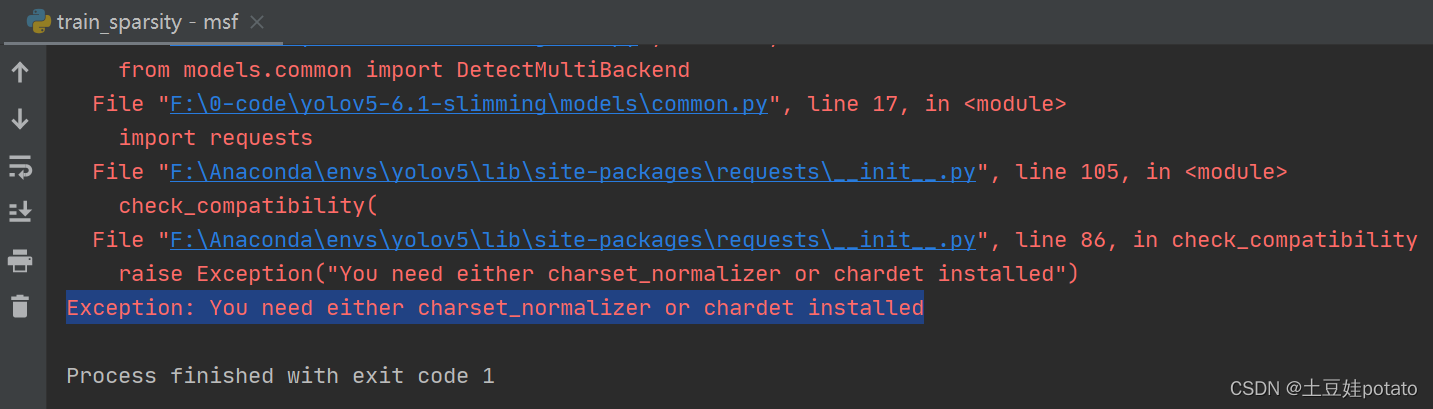
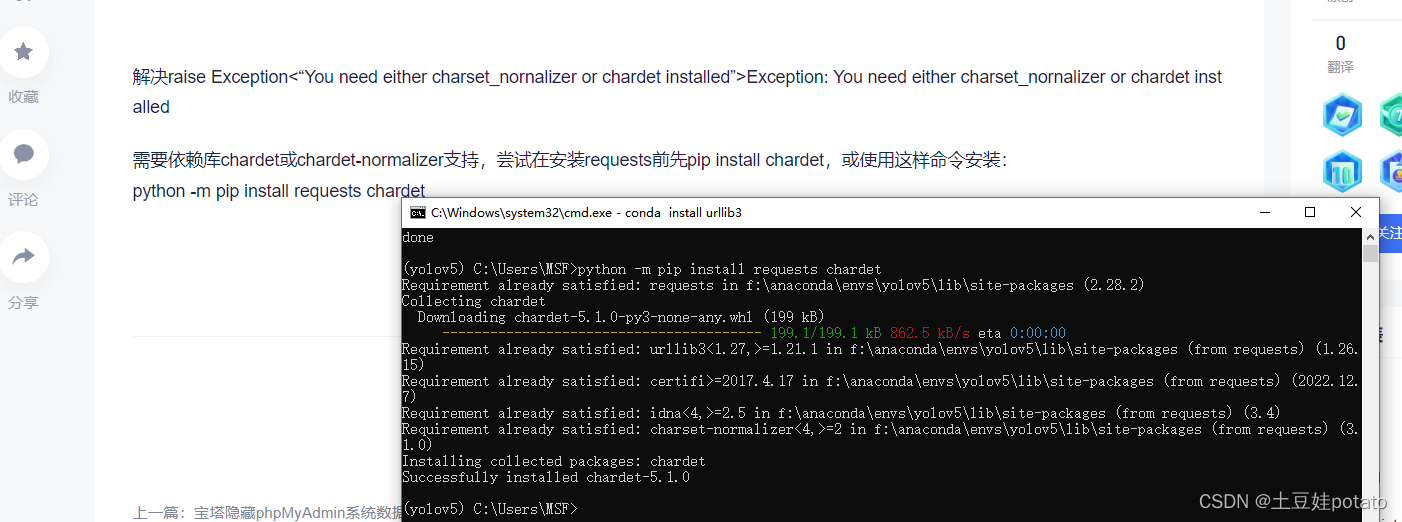 解决raise ExceptionException: You need either charset_nornalizer or chardet installed
解决raise ExceptionException: You need either charset_nornalizer or chardet installed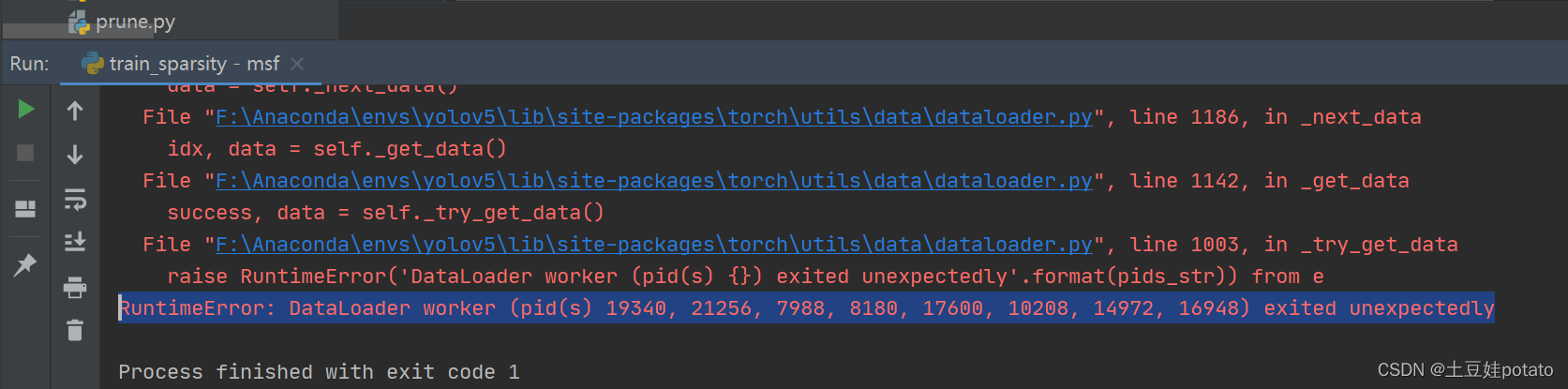 并没有显示出是哪一行代码出错,但是根据提示中的DataLoader worker可知是多线程的问题,对应到代码中应该就是下图这里:
并没有显示出是哪一行代码出错,但是根据提示中的DataLoader worker可知是多线程的问题,对应到代码中应该就是下图这里: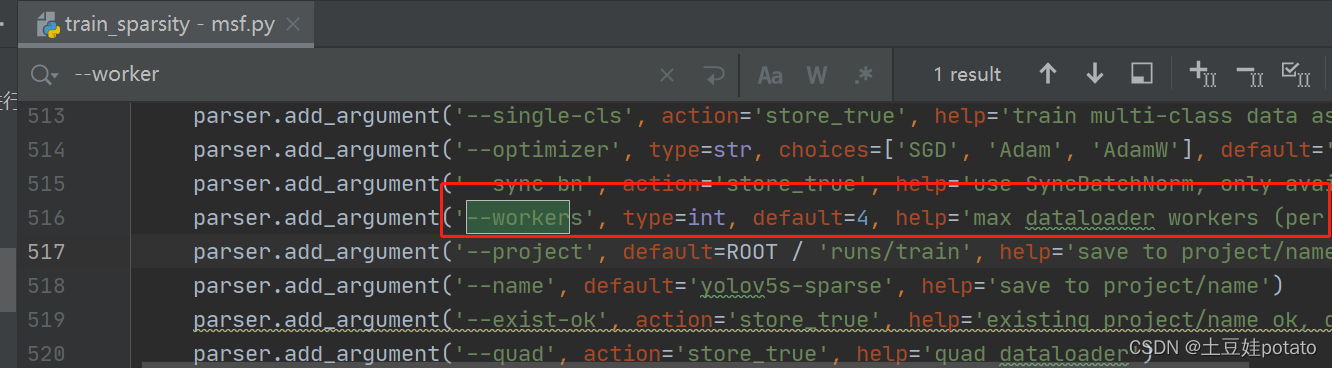
【本文地址】